

2024-03-08
ProductAutoDocs: Automatic Documentation for your Analytics Events
Analytics events are the backbone of your data stack. Nothing can provide more value than a bespoke tracking plan you and your team designed, tested and implemented.
If you’re lucky, success happens. Scale happens. New events and properties get added, you start “cross-utilizing” events beyond original intentions. Engineers start adding unexpected events. C’est la vie.
The modern reaction to this has been schematization. These data contracts aren’t just about code, they enable control & oversight, usually by the data team. They also introduce a ton of new process & development complexity.
What if you could achieve many of the benefits of schematization, without hindering developer productivity, without compromising the events collected and without introducing new technical complexities to your system?
👋 AutoDocs
We’re building something new, aiming to solve two major pain points every data team encounters.
(1) Event Cataloging & Exploration 🔎
If you ask questions like:
- What events fire?
- What properties do they include?
- What format does this timestamp field use?
- Does this numeric property have decimals?
- What’s the distribution of values for this field?
We’ll traverse all your events to collect statistics and samples at both the event and property levels. Then we serve them back to you in a simple tool built for search and later on, collaboration.
(2) Event Change Detection & Alerting 🚨
If you ask questions like:
- When did we first start sending this event?
- The number of events in the new version seems fishy?
- What properties changed?
We maintain a state of your schemas on a per-version basis. Some example alerts:
- Cardinality changes: In version 1 there were only 3
platformvalues, now there are 47 - Type changes: A property that was previously an
intis now astring - Occurrence % Changes: How often do specific properties appear on each event, and if they’re present, are they null (or empty arrays)?
Things that, ideally while in pre-release, you can fix to prevent downstream issues from ever really happening.
Event Exploration
Our system is built to safely crawl even the nastiest of your JSON payloads, collecting all the paths, sample values and storing statistics. We know your events aren’t flat, so full nested crawling of both objects as well as object arrays is supported. We make it searchable and clear to understand what is being sent from your games, apps, services or websites.
If you’ve ever:
- Run a
SELECT * ... LIMIT 10query, just to figure out what an event looks like? - Had to
SELECT DISTINCT X FROM table WHERE ...just to remind yourself of the proper capitalization being used? - Sent a Slack: “Hey team, what events do we have that record the user’s CPU model?”
This is for you!
A Collection of JSON payloads like:
{
"event_id": "0b5407c4-0a4a-4127-9741-0bba85728a24",
"user_id": "85lX",
"meta": {
"version": "1.0.0",
"event_timestamp": 1704744000,
"event_dt": "2024-01-08T20:00:00Z",
"device": {
"platform": "ios"
}
},
"event_name": "AppOpen",
"event_family": "Lifecycle"
}
Yields (WIP UI):
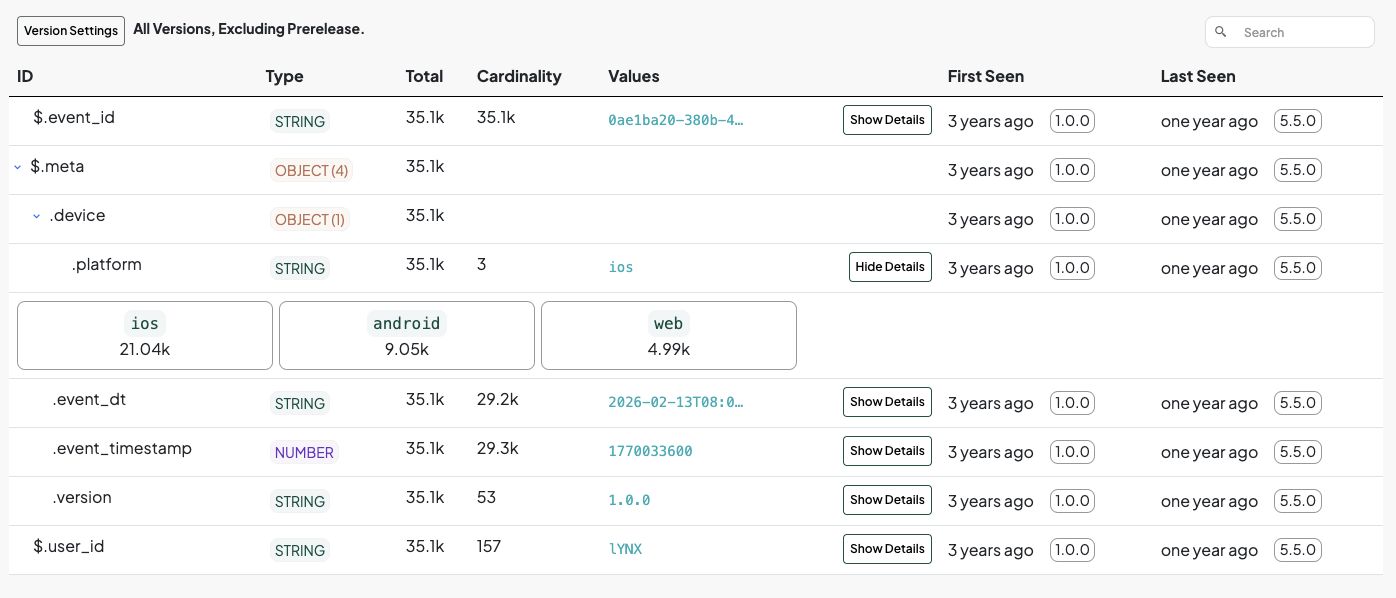
You may be thinking
“In my situation, the way events are really described is split between multiple fields. We have an
eventTypeand aneventName.”
Don’t worry, we don’t like to make assumptions here. Similar to how ingestion works, you’re in control. You can define up to 3 descriptor fields for your detection setup. You can also use this to, for example, compare implementations between platforms emitting the same events.
One of the most exciting post-launch features we’ll be building revolves around making this a collaborative effort. Enabling users to annotate and add documentation about events and properties. Imagine being able to onboard a new analyst and point them towards a fully defined dictionary of all the raw events you collect, with examples of how they’re used, gotchas, sent values, and more.
Event Change Detection
Whilst traversing your events looking for descriptors, we also look for a supplied version field. With that, we further delineate the collected events & properties to enable a “release notes” experience for you to compare between versions. Further, we separate releases in a “prerelease” state so you can get an early look at changes while testing. The release and QA process around analytics is an extraordinarily hard problem to solve. We hope to make it a little bit easier.
We also aggregate everything with a time-dimension, to enable even more interesting stats on your event and property patterns.
Here are some more WIP screenshots:
In the spirit of a changelog, we want to provide you an at-a-glance view of each version release, with new/removed/changed events & properties.
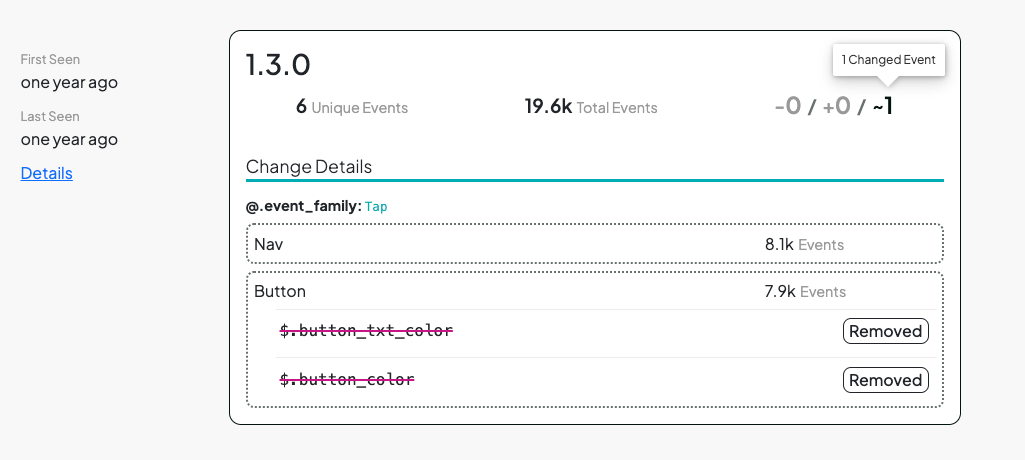
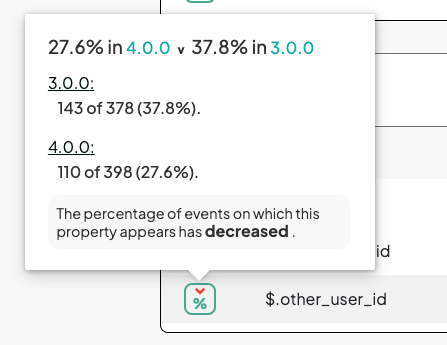
In this example, we see a change that may be expected.
Our imaginary app added a group chat feature, introducing a new group_id field and the existing other_user_id field started having NULL values in the case of group messaging. This is another spot where collaborative annotations will manifest.
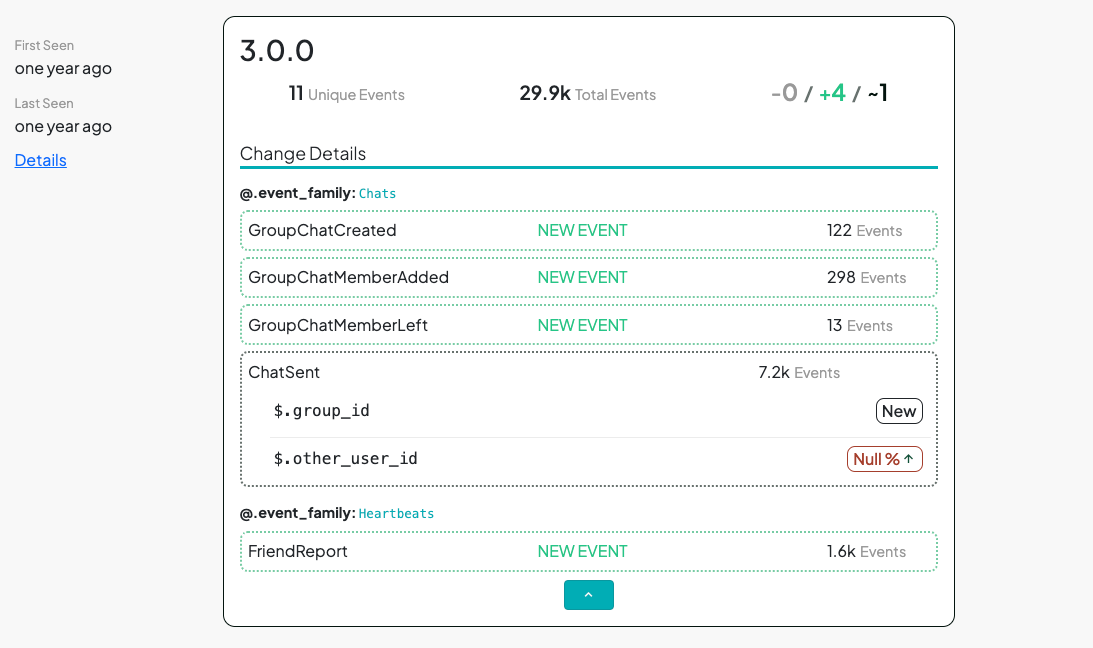
You can also dig into arbitrary version-to-version changes.
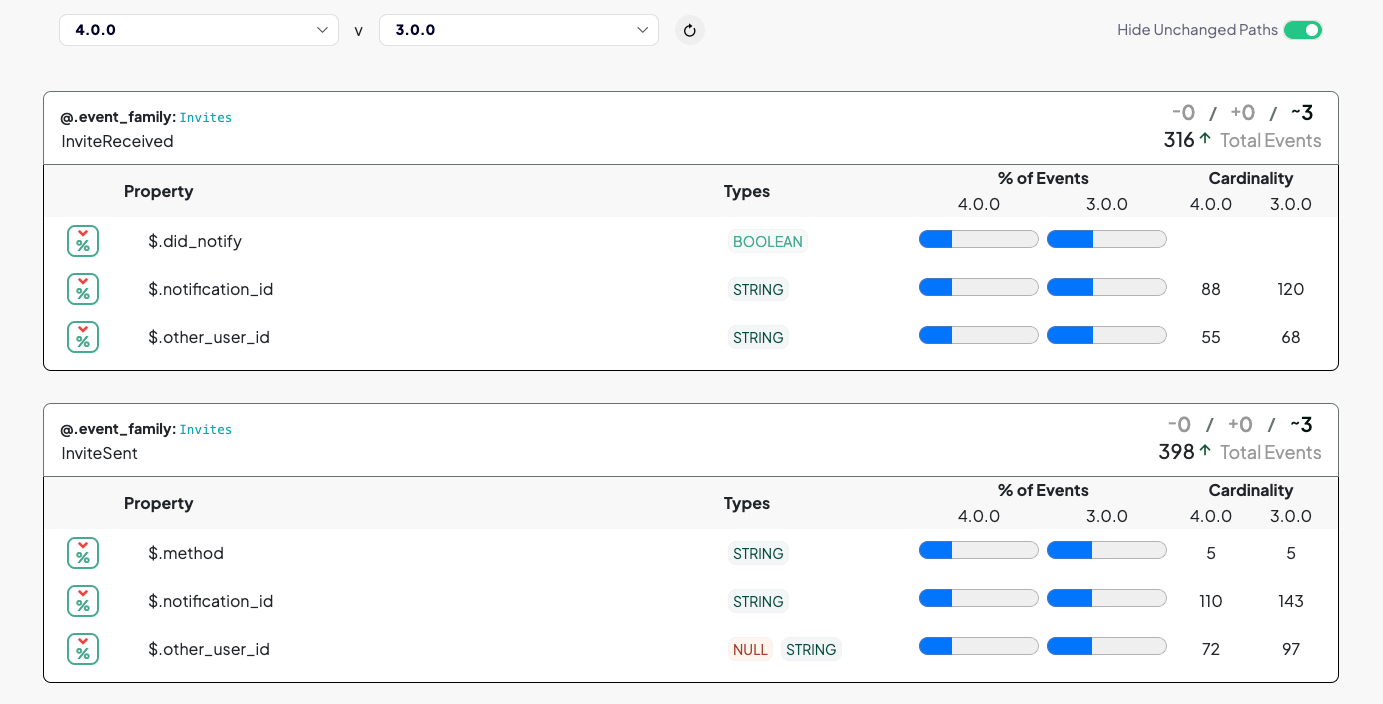
Changes in Invite events may point to other issues
Privacy & Security
As with all our products, we are focused on ensuring the security of our systems while protecting the privacy of our customers’ data.
For real-time metrics, this was pretty simple to solve: just don’t hold onto any data.
In this case, we’re still not retaining any raw events. We are however cataloging property values, which may contain some sensitive data. Our normal security policies apply — data is isolated, never comingled between customers. Access controls & permissions are strong. But the entire process has also been implemented from the beginning with user choice in mind. Let’s say you don’t want to hold onto samples of the @.user.email field — that makes sense. Simply add it to your ignored fields. If you do this after detection has begun, we’ll clear our history, and note it in the UI. Within seconds, any ongoing detection will stop recording the field and hold onto only hashes for cardinality calculations. We want to make this easy for you.
In the future, we may even add PII detection, if that’s a useful feature to flag unexpected and/or undesirable data from ever being collected.
Coming soon
In the next few months, we’ll be going live with AutoDocs. For now, it is going to simply be an additional feature of Aggregations.io. As we work with beta testers, we may realize the need to have a slightly different cost model, because the stored data is far different than that of time-series metrics. We intend to be very transparent about this.
Interested in trying it out? Send us an email: autodocs-beta@aggregations.io.